On Learning, Part 1
Learning As Theory of Everything

Part 1 of a larger essay. Part 2 is here.
I. Learning Math
We’ll start small.
Imagine you're back in school. I tell you to simplify:
You work out the answer. I tell you: no that's wrong. I sound confident, so you glance back over your work. You're pretty sure you remembered order of operations, but maybe you misread something? The denominator is clearly a trick. Am I messing with you? Maybe I'm wrong. The "÷" looks like grade school math, but "*" is a little weird. Maybe I mean something else by it? If so—rude. You might ask me what I think the right answer is, so you can figure out what's going on...
This illustrates how the human mind "learns from an error", when the subject is familiar.
If instead I gave you a page of math problems on a subject brand-new to you and at the edge of your ability, you'd expect to get some answers right and some wrong. You'd look carefully over the wrong ones to figure out what you missed. The errors "point to" the misunderstandings. If you stare at these long enough, comparing to the right answers or to worked examples, you will hopefully be able to iron out the wrinkles in your mental model and arrive at the right understanding.
I can't give you an example of that because I don't know what you're bad at. Instead, consider the following and solve for x:
At one point in your education it would be reasonable to assume h is a variable and the solution would be
Once you learn the notation f(x) for a function it becomes ambiguous; h as a function would probably be the better guess and
should be its solution. If I'd used f instead of h you'd be more certain. Here, the best response is probably to ask me what I mean and to express some irritation at the ambiguity.1
This second example illustrates how new material is learned. You acquire through practice two mental gestures of "multiply numbers" and "call a function", and— separately—learn how to pattern-match these gestures to language, in this case by starting with only the multiply rule and then cleaving it into two rules depending on the current context (here, the definition of h). Trace these two to grooves long enough and they'll both become second nature.
That was a warmup, to help remember what learning feels like firsthand. My eventual goal is to say quite a lot about learning in general, but first, to keep things concrete, we're going to need a lot more examples. It's 2025, so let's start with AI.
II. Learning in AIs
Here's a cartoon of an AI model:
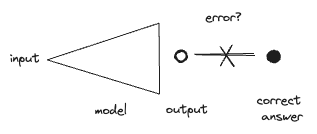
The triangle stands for an AI model, depicting as receiving an input on its left side and producing an output on the right, which is then checked against the right answer.
It's not all that interesting to think about what an AI has to say in response to a single input, so instead I'll depict it as responding many inputs at once, like this:
Some right answers, some wrong; the errors are marked with xs. If this errors are fed back into the model in a clever way it should be possible to improve the accuracy over time.
That cartoon is a mess, so I'll simplify it like this:
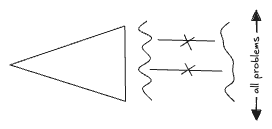
Now I've drawn the output as a wavy curve representing the responses it the model would give to all possible math problems. This can be compared to the "correct" wavy curve, The difference between these, the "error", ought to contain the information needed to train the model.
So let's draw that training process:
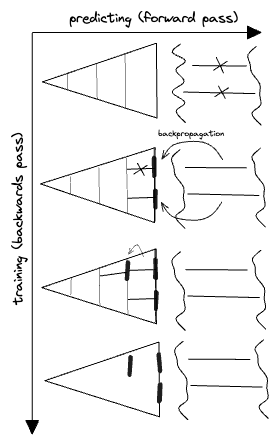
Here I've divided my cartoon model into five layers—one input layer, three intermediate, and one output. The training algorithm has first attempted to fix the two errors by updating or patching the output layer—these are the thick lines that look kind of like bandaids. This works, but introduces a new error inside the model, so the algorithm does the same thing again to introduce a patch in the fourth layer. With this all the errors are handled, and training is complete. We're left with a new model which differs by three updates from the original one.
I've given the alternate names forward pass for prediction and backward pass for training. I'll prefer these as general names for this dichotomy, since it won't make sense to call these predicting/training in most of the examples of "learning" we'll come across.
This iterative process of working backwards through a model to locate the specific places to be updated is called backpropagation. The term is used in a few closely-related ways in AI, but I will employ it in a specific way which is hopefully not too confusing: backpropagation will be something you do with errors to or through a model, assigning those errors to specific locations in the model which needs to be updated, like my arrows in the cartoon. How you actually update the model at the point can vary; the basic algorithm used in AI is "gradient descent" but others are possible.
I find it extremely useful to be able to distinguish this action from the larger learning process, so I'll use backpropagation as a general term. We could also use it for the math problems: backpropagation would be the step where you examine your assumptions to find the specific point of error.
Got all that? Next up: games.
III. Learning at Games
Consider the game "Twenty Questions". You guess a secret word by asking: Animal, vegetable, or mineral? Is it larger than a brick? Etc. Here the tree of questions you would could ask amounts to your "strategy"; this is the analog of your "model". You could—if you wanted to—improve your strategy as if training an AI. You'd play loads of games and use the outcomes to incremental improvements to your tree of questions, like this:
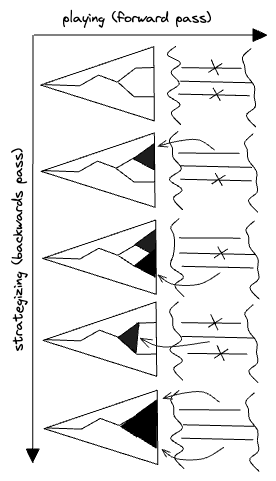
Much of this looks the same as before: there are forward and backward passes, and backpropagation of errors, and the model still has a sort of layers, with the earlier layers being your earlier questions/guesses; there are fewer of these as, obviously, it makes no sense to, say, ask a hyper-specific question as your second out of Twenty Questions.
The "learning process" depicted here differs from AI training in a few ways. For one, the errors are fixed one at a time—this works more like correcting a math problem, where you'd search for specific mistakes in your calculation.
Another difference: when the first two errors are fixed, a new error slips in. In Twenty Questions this would mean there is some secret word which the original tree of questions would have been able to guess, but which the slips through the cracks of the new strategy. It's not enough to modify only the final round of questions—to do any better, an earlier question has to be changed.
Tweaking an earlier question is then depicted as reintroducing the original two errors (or something, I'm not being all that precise here). But there turns out to be a set of choices which "solve" all three at once, which can be found in one or two more steps.
A similar situation which may be more familiar arises in Wordle. If you have two guesses left and you've narrowed the solutions down to, say, "trace", "grace", and "brace", then guessing one of these followed by another would only win two-thirds of the time. But if your second-to-last guess is some other word which uses two of the letters, like "great", you can win every game. This isn't quite the same—actually it's a bit more interesting—but it shares the basic structure: the best strategy cannot be reached by tweaking the last guess, nor by improving any single guess—these updates are too low-order. Instead you have to make a high-order update to your strategy, altering multiple decisions at once, in order to make progress.
This low/high dichotomy will be an extremely useful way to think about learning. Every model update which changes a single decision point as equally low-order, even though some decisions come "earlier" and some "later" in the game. What makes an update "high-order" is that it alters many decision points at once—usually it affects an entire "subtree" within the strategy, rooted at some early-game decision-point. Once that early-game decision is altered, some additional low-order steps are typically required to arrive at a new optimum, as depicted in the cartoon.2
In general there are more high-order updates you could make than low-order ones, and they're harder to find, and even when you find one it can hard to tell if the final result with all the subsequent low-order updates is actually going to be an improvement. You'd clearly prefer a low-order update if possible; this fallback from low- to high-order is the analog of "recursing backwards through the layers of an AI model", and is characteristic of backpropagating errors into strategies.
Because it is comparatively hard to tell if a high-order update is going to make an improvement, learning a strategy ends up feeling like "searching in a maze". You will sometimes have to commit to a route only to backtrack later, and in a sufficiently-complex maze it will help immensely to be able to use a heuristic like "I know I need to be going generally north" or "it feels like it's getting warmer" to guide your search process, lest you wander forever.
For a sufficiently complex game like chess (or math), even this kind of naive backpropagation is basically hopeless, and you will never get anywhere unless you step back and try to analyze the game. Wordle, for example, could be analyzed and "solved" by doing the math to find the best of guesses. I will think of these kinds of shifts from "altering single decisions" to "heuristics" and "analysis" as being one long spectrum of ever-higher-order updates, like so:
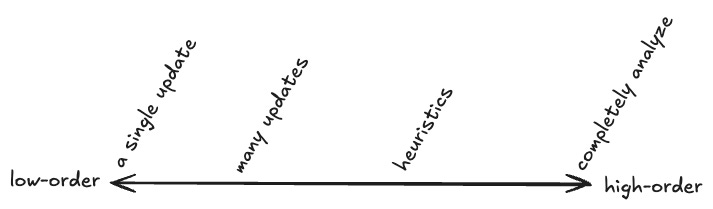
Learning in humans, as we'll see in a bit, can look like either of the last two example examples: active learning (such as that used for math) works much like the learning of strategies in this section, while passive learning (such as for motor skills, or building mental maps) works like that of an AI. So our "map" of the learning process is beginning to fill in. Let's continue.
IV. Learning in Evolution
Evolution (natural selection, Darwin, etc)—fits easily into the learning process. Here the "model"—the thing doing the learning—is the entire gene pool of a population or species, with the model's “performance” being the fitness of the population as a whole (as opposed to that of the individual). The process of natural selection "learns" a genome which is fit enough to survive in its environment; to fail to learn is to go extinct.
Unlike the earlier examples, the "learning" at work in evolution is not aimed at solving a single "problem" optimally—there is not, generally, an incentive to be "as fit as possible". Instead the aim is long-term survival within a broad and slowly-changing range of environments, which at any time will tend to be centered around some "typical" habitat of the species.
In the domain of evolution, "low-order" updates the mutations of single base-pairs (A to T, C to G, etc), while "high-order updates" would be those requiring many mutations: base-pair flips, insertions, deletions, etc. Examples of "high-order" updates would include new proteins or tissues, or as an extreme case an entirely new organ, the classic example of which is the eye, whose complexity at first glance seems to sink the whole theory of evolution—but the existence of ample evidence of lower-order mutations incrementally paving the way is enough to restore it to plausibility.
It is useful to visualize evolution as wandering across an abstract "fitness landscape”. The "distance" between locations has something to do with the "order" of the update required to get there, with high-order mutations traveling larger distances, while the altitude represents fitness. Visually:
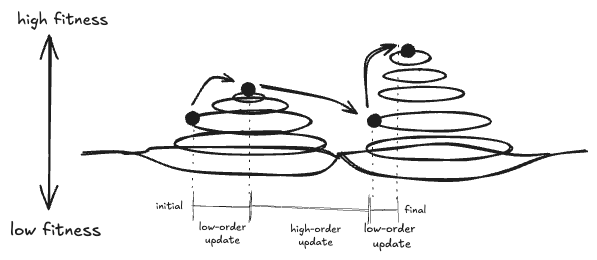
The "landscape" view makes apparent the importance of "high-order" updates to a learning process: without the ability to take long distance hops, there can no way to exit the neighborhood of a particular "mountain"—which will be a death sentence if the mountain's peak turns out not to be high enough to survive.
This is a good opportunity to introduce a couple more general features of learning.
The first is parallelism: a species of course consists of many individual organisms whose genomes would actually appear as a cluster on that fitness landscape. This obviously helps avoid randomly being wiped out. But it is also advantageous to a species, viewed as a whole, to maintain a good degree of genetic diversity, in order to increase its ability to "explore" the space of possible genomes and the fitness landscape, which increases the chances of stumbling upon valuable high-order hops. Here we see the other side of the typical "explore vs. exploit" trade-off, familiar to gamblers and foragers, with natural selection itself doing most of the "exploiting" already.
The second feature, closely related, is the trade-off between short-term and long-term fitness: a species needs to be robust to environmental changes. This too is aided by keeping a broad gene-pool around, as you never know what genes you will need when the external world shifts under your feet. This also implies that the maximization of short-term fitness—i.e. hyper-growth—is generally not going to be selected-for in the long term, both because it will over-specialize for the current environment and because, taken far enough, such a species will usually destabilize its environment rapidly and go extinct (think of cancer or viruses).
Both of these features imply that "diversity" is an element of population-fitness itself, and that, up to a point, the mechanisms which contribute diversity to the gene pool will tend to be selected-for in the long-term. Two examples are sexual reproduction and recombination, in which existing genetic code is are mixed up during reproduction.
I ought to note: the exercise I’m undertaking looks quite a bit like the idea of Universal Darwinism—that all sorts of processes can be seen as examples of a general phenomenon of evolution. The difference is that I’m identifying “evolution” as a special case of “learning”, rather than the reverse, as, to my mind, the characteristic features of learning are rather more fertile than those of evolution—in particular, the possibility of directed, active learning, which narrows and augments the random process of evolution so as to span far greater distances in the model space.
V. Learning in Science
One last example of learning: scientific progress.
Here the "model" being learned is the entire scientific community's body of knowledge, and its accuracy can be seen either as the predictive power of that knowledge, or as the extent to which that knowledge is able to improve peoples' lives. Low-order updates look like small and incremental improvements, while high-order updates would be your major paradigm shifts, with the quintessential—or "paradigmatic", excuse me—example being the Scientific Revolution culminating in Newton's discovery of physics.
It's easy to connect the "scientific method" to the various features of learning-processes we've already seen. Anomalous data or unexplained phenomena raise questions—these are the "errors" which demand to be "backpropagated" against the theory. The scientist tests different hypotheses by repeatedly gathering data (the forward pass) and trying to explain it (the backward pass), incrementally building up a big-picture (a high-order model update) out of small-pictures (low-order). The work is finally finished when all the anomalies can be explained (in the first sense of "accuracy") or all peoples' lives are perfected (in the second); obviously neither of these will ever happen.
More connections: on the way to the final theory, science will fan out broadly, entertaining many inadequate or partial theories "in parallel", both across many researches and within the mind of a single researcher. There will be numerous dead-ends: models which are plain-wrong, or questions so hopeless as to be not worth pursuing, or small models which are successful on their own but which will eventually be put on firmer ground by assimilating into a larger theory. In any of these cases a researcher must backtrack and return to something more promising—the short- vs. long-term trade-off applies; no one has infinite time or resources with which to search for answers.
It is typical of theoretical science that, when the right high-order theory is identified, a huge amount of answers will "snap into place", and many parallel lines of investigation will be quickly consolidated. The history of science—here I'm thinking of evolution, relativity, or the double helix of DNA—demonstrates how, when a science has "broken through" with the right high-order update, a flood of research ensues to "exploit" the breakthrough by exploring the new heights which then become accessible—quite a bit like the discovery of a new "continent" in the landscape picture from before.3
Science is therefore at the extreme active end of the active/passive spectrum learning, so much so another concept is new needed in our vocabulary of learning to name the crux of scientific learning. This I call model-synthesis. It is the "hard part" of science: the constructing of an entirely-new model which accurately reflects the nature and causal structure of the underlying reality.
Model-synthesis is the critical step because, without having in mind a model which matches the truth of reality, one cannot generalize results far beyond the experiment in which they were determined. Take eclipses: being able to predict eclipses is helpful—for what? for predicting other eclipses, and perhaps a few related astronomical phenomena. And it's useful as data if you want to figure out how the planets actually move, which in turn is useful if you want to work out the laws of physics. But the reverse is far more powerful: knowing how the planets move makes predicting eclipses completely trivial, and understanding how physics works makes predicting planetary motions trivial—and much more besides. Reality, it turns out, operates according to very few fundamental rules, and most phenomena can be conceptually broken down and identified as the interaction of just a few of these rules. A model which captures the underlying rules of reality, then, will tend to generalize extremely well—these are the sought-after "high-order updates" of scientific learning.
The story of the Scientific Revolution illustrates what model-synthesis looks like in practice. At first there are a great many disconnected and not-especially-effective models entertained in parallel. One-by-one these are invalidated, and anomalous observations accrue, all of which seem to "point to"—backpropagate towards—the possibility of a unified theory. As more of what-people-know is invalidated, a kind of "anxiety" sets in, with numerous models being in consideration in parallel, but with little that can be said for certain.4 Among these some win out: impetus, Copernicus' heliocentrism, Kepler's laws, Galileo et al on kinematics, Bacon et al on the principle of empiricism—and the search begins to narrow, though at this point many of these sub-models are not yet grounded in firm principles, instead only predicting patterns in observations, or established on the basis of analogies (the analog of "recombination"5). Finally the much-needed "synthesis" is achieved—Newton's physics—and many of the submodels snap into place. The search has converged to a model which clearly wins out, and the many alternate theories can be discarded. Plenty of details remain to be worked out, of course—arguably we are, to this day, still working them out.
A form of "model synthesis" also occurs in the other learning processes we've seen. In the math problems "synthesis" occurs at the moment when you figure out what's going on. LLM-style AIs don't do model synthesis explicitly, but plenty will happen anyway in the course of many iterations of training. Evolution works similarly: the DNA "model" for an organ clearly has to be synthesized at some point, but this largely occurs by chance, aided along by mechanisms like recombination.
Scientific learning, though, hinges almost entirely on the "model synthesis" part of the learning process. I'm tempted to declare that it is model-synthesis specifically which makes a learning-process a "science" at all—to do anything scientifically is to synthesize an accurate model of it, isn’t it? This is contrary to what one might think after learning about the "scientific method" in school—the testing of hypotheses is really only a small piece of the picture. It is contrary, too, to most of what is called “data science” in business culture.6
I think of the sophistication of model-synthesis in terms of the low- to high-order spectrum. At the low end we have "no model at all": modelling all data as "just-how-things-are", whether by chance or as the will of the gods; this was the "before" case for much of what later came to be explained by physics. Next comes predictive modelling, or "pattern recognition". Better still is to work out explanations for those patterns in terms of fewer and simpler things, parameters and the like; here we find "statistical inference" and Bayesianism7. Finally we come to the holy grail: an accurate representation of reality. It should be said, though, that even a perfect model of reality will always be based ultimately on some observation of "just-how-things-are"—even physics, which is better-understand than probably else in human knowledge, is ultimately rooted in some twenty parameters and some general principles, all of which are only known on the basis of observations.
With that we will conclude our tour of examples.
VI. Learning in General
Now let’s examine some of common features of the examples we’ve seen so far.
In each domain the learning process would typically be repeated in a cycle—either until some objective was reached, or interminably. You could carve it up a slightly different ways, but a basic cycle should look something like this:

Each of these steps will generally occur in a loop and also hierarchically: small patterns are synthesized into low-order models, low-order models combine into to higher-order models, etc.
I find it useful to have names for all of these individual steps. Colloquial usage would elide the distinctions entirely by calling almost all of these steps "learning". And when the distinctions are elided, it is the usually subtlest parts of the process—"backpropagation" and "model synthesis"—which tend to go unrecognized.
The relative importance of the different steps varies among the various examples of learning. Active learning (typically human: math, science, and strategies) will tend to search in ways which are narrowly targeted at model-synthesis, while passive learning processes (AI, evolution, and unconscious skills in humans) will emphasize backpropagation and pattern-recognition.
The low/high-order dichotomy is very general, as is the "fitness landscape" picture. One should not, though, take the "landscape" too literally: the actual "space" of model-updates almost always has far more than two dimensions (there are roughly few billion first-order mutations to the human genome, square that for second-order, etc...) which is why good high-order model updates are so hard to find.
For some problems the landscape will make more sense turned upside-down, with "up" as "less accurate" direction, such that "learning" can be seen as "flowing downhill" and the mountains become valleys.
It's worth drawing attention to a particular feature in the landscape view: the importance of hard-to-find intermediate steps which allow a high-order update to be build out of a series of low-order updates—think of building bridges between the islands of an archipelago, or of a narrow gap or tunnel through a mountain ridge. Interestingly, the existence of such "land bridges" is a property of mathematical reality: a learning process cannot find such a bridge if one does not exist within the range of the highest-order hops the learner is capable of making. (I think of a biplane hopping between islands, or miners tunneling through mountains but having to, I don't know, come up for air? The islands have to exist.)
Now we come to the two trade-offs which arose throughout our examples. First was the trade-off between short-term vs. long-term accuracy, and second between exploring the space of models vs. exploiting a model which is working, or is at least good-enough in the short-term. They are very similar, and each arises from the fact that all real learning problems are operating under constraints on the amount of time that can be spent learning, and on the amount of "working memory" that can dedicated to the learning process. The latter idea is rather broad, and includes "how many organisms of a species can try different mutations at once" as well as "how many ideas you can hold in your mind".
While these constraints may seem like minor afterthoughts to the general picture of learning, they are actually very close to the heart of the matter. These constraints are the causes of many of the ways learning can fail, and those "failure modes" in turn are more-or-less the whole reason that "learning" will turn out to be a useful "theory of everything".
The basic problem caused by constraints is this: high-order updates which dramatically improve accuracy are rare. They have to be searched for, and usually must also be synthesized out of many lower-order updates. Searching and synthesis both take time and memory: you have to be able to backtrack from dead-ends, to hold onto lots of data at once to recognize patterns, and to try many ways of recombining models to find the best synthesis. Furthermore, it is hard to even recognize a winning update when you find it, as you will usually have to fill in many of the details with numerous low-order epicycles to see improvement at all; working-memory limitations prevent you from seeing so far ahead.
Therefore there is an upper bound to how good of a model-update you're going to be able to come up with. If you have to find something better than this limit to survive or succeed, it just won't happen—learning won't "converge"—and you'll fail at whatever it is you're trying to do (e.g. a species will go extinct.)
This in turn means that it is advantageous to direct one's learning towards "good-enough" solutions, which involves heuristics, in two separate senses: first, heuristics for learning are used to identify promising directions and to judge an update as “good-enough”, and second, that the "good-enough" solutions you come up are themselves almost always going to be heuristic approximations to the "true" optimal solution.
Additionally—and really this is the more fundamental implication of constraints—the forward pass in any learning domain also draws on the same resources of time and memory. Almost no real learner can actually spend all its time learning, because the whole point of learning is to be able to do something better, and doing-that-something is not free! Evolution, for example, can't just wildly experiment with mutations, because every intermediate organism has to be fit enough to survive to reproduction. And a scientist can't just dream up theories all day: typically they will have to feed themselves and the like, and this in return requires that some of their mental energy be devoted to working and dealing with the world. (AI training is basically the exception to this rule, but if you consider the company training the AI as the "learner", the threat of bankruptcy works similarly.)
The need to live while you learn again requires that you employ heuristics. A good and very general strategy is to search until you find a heuristic that is good-enough to survive—relative to the ambient level of risk—while learning continues in the background towards longer-term thriving. Survive/thrive then is another trade-off we could emphasize, though it is hardly any different from the others. For yet another example, I think here of startups trying to target a "default alive" state while also investing in growth; obviously it helps if your investments in growth can convince other people to keep you alive. (The domain of business would make an excellent example of learning, except that I don’t have a lot to say about it. It must be left as an exercise for the reader.)
All of these trade-offs imply the same thing: that heuristics are the name of the game. The central problem of most learning turns out to be closer to "how good is good enough?" than "what is the right answer?" Math and science are really the exceptions in this respect.
If you're curious, this whole essay so far is more-or-less what you would have seen in an undergraduate computer scientist's intro-to-AI course circa 2010, before neural networks took over the whole curriculum. Of course you would have also seen most of these ideas in some form in the study of evolution, too, or philosophy of science, economics, psychology, business. But it seems to me that it is especially instructive to look at many kinds of learning in parallel—in fact, the theory of learning itself suggests that this would be so; what I've done here is the "pattern-recognition" step of the process, and some amount of rudimentary model-synthesis. We're learning about learning.
But, as I've just established, one can't just learn forever. Now that we've learned something about learning itself, we can turn this model around and start to see what it has to say about some more important problems.
Part 2 is here.
In high-schoolers I’ve tutored, this particular collision of notation consistently confuses and offends. They tend to struggle for a little while, getting it right in obvious cases when suggestive symbols like f and g are used, but being more likely to have trouble parsing an expression when an uncommon symbol appears. It helps to address the ambiguity directly. But frankly, they're right: if math were software, I would consider these clashing interfaces to be unacceptable in code review. But math, being set in books, is much harder to change.
“Low-” and “high-” order take their names from counting in binary where 0110 is followed by 0111 but then by 1000—when the left-most or "highest-order" bit, flips the rest reset to 0. These sense is that a higher-order change tends to reconfigure all the low-order bits at once.
I got confused writing this because "low-order" has as sense of "imprecise" in calculus. The two senses roughly coincide when thinking about a low-order numerical integration algorithm. Low-order approximations will typically be unable to express "high-order phenomena" like periodic orbits, conservation laws, or feedback loops.
People have been arguing for years about the relative importance of, or credit due to, these paradigm-shifting breakthroughs. I don't really have an opinion on this—I think it depends on what you take "importance" to mean, and credit will go where it likes—but I think it is incontrovertible that the famous and named "breakthroughs" lead to considerable consolidation and unlock new regions of theory-space.
That the Scientific Revolution threw out so much of what had been taken for granted was the sentiment behind Descartes' "I think therefore I am"—when everything has been thrown into question, can anything be known? Only my own existence, nothing more. He was being rather dramatic. For an extremely-readable account of the whole story of the Scientific Revolution, I highly recommend Butterfield's "The Origins of Modern Science", which was among the books that inspired Kuhn’s “Structure of Scientific Revolutions”, and has the advantage of being delightfully-written rather than bone-dry.
In physics, the identification of “inertia” was aided (and also misled by) the analogy with heat dissipating from a red-hot iron, and gravity's action-at-a-distance was aided by analogy with magnetism. Analogy is the name of the game—we rarely, if ever, mint a new thought from scratch.
My brother has an essay on this: Data Science Isn't.
“Bayesian inference" is frequently used as a paradigmatic example of learning, but it seems to me that Bayesian inference brings to mind only a narrow kind of fitting of parameterized statistical models. This fails to capture the real crux of learning, which is how you actually synthesize a good model by searching the space of all possible models.